JellyML. The why.
by Michael Mulet (January 30, 2023)
How many times have I done this?
- run an experiment
- make some changes to the code
- experiment again
- oh no, it's worse.
- change back to 3 experiments ago,
- or was it 2 experiments ago?
- which git branch went with this model checkpoint?
- why do I have 100 branches?
- did I remember to commit?
- okay, I did remember to commit, but did I remember to make it a new branch?
- repeat until you get the results you want
Well, let me tell you, I have done this many times. Each time seems just a little bit more painful than the last.
I finally came to the point where enough was enough, there had to be a better way.
After a little brainstorming, I thought up the solution of embedding the code into the model checkpoint. Checkpoints are usually GB in size, so a few MB of code is not going to make a difference. One checkpoint maps to one commit. Where are the commits? They are in the models. Simple.
That's how JellyML was born.
I started implementing it by doing some really exciting things with importlib, tracking all of the imports, and some hacky things with LD_PRELOAD to intercept what files were being opened. Luckily, I only worked on this for a little bit before I realized that I had nerd sniped myself.
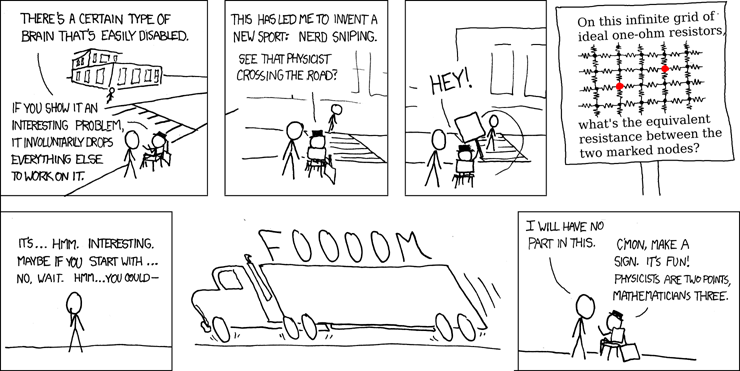
Don't get me wrong, I love following the white rabbit down a hole of cool hacks, but I have other goals I need to accomplish.
The solution, hopefully the right solution, was to use git.
With that out of the way, I had some sub goals that I wanted to accomplish with JellyML:
- First, I wanted to load a snapshot without using "torch.load"
- torch.load uses the "pickle" module which has a lot of security issues. (Although, it is safer to use with torch.load(weights_only=True))
- torch.load loads all of the tensors into memory, which may not be possible if you save the tensors on computer A, then try to load it on computer B.
- Second, the code should be saved in a way that works with both pytorch and pytorch lightning
- Third, a lot of users may only have a passing familiarity with git, so I wanted to make it so
you never have to touch git directly.
- To that end, I wanted to never lose any information. Everything that JellyML does should be reversible. And it should be easy to go back to any previous state. If JellyML loses any information, I've failed (and probably made an enemy for life). This means saving all changes in your working tree, including untracked and uncommitted files.
- Fourth, if someone is familiar with git, they should be able to use git as they normally would. JellyML should not get in the way.
I think I've accomplished all of these goals. I'm pretty happy with the result.
I tried to keep the interface (the api and the command line) as simple as possible. I've tried to make it so that if you do something wrong, you will get a helpful error message, and a way to fix it. I know that I am dealing with your work, and there is absolutely no room for error. In the end, I think that the development of JellyML was 5% programming, and 95% thinking about what could go wrong. Which, I think is a good ratio for this kind of project.
A.I. Usage
It would be kind of a shame to not use A.I. to generate some of the content for a program that is all about A.I./M.L.
-
I modeled and animated all of the 3d models for the website myself (in Blender), but I did use depth-guided Stable Diffusion to generate most of the textures for the diner. I really liked how the textured donut used for "Figure 1" turned out. I had to make the sprinkles myself, but the rest of the donut is from the depth-guided Stable Diffusion.
The modeling was easy. At the top of my A.I./M.L. wishlist is an A.I. model for animating. Animating takes the most time. In the end, I do think that the jelly tentacle animation turned out pretty well, but it was a lot of work. Same goes for the fluid simulation that was also very time consuming. If anyone has some models for those tasks, I will be happy to port them to Blender. Let me know.
-
I wrote the code for the website, the blog post, and the python library while using GitHub copilot suggestions. This saved a lot of time. Copilot continues to be worth every penny.
-
I mostly used GPT-3 davinci (with a little bit of ChatGPT and copilot) to write the puns and puzzles for the puns and puzzles box.
Mixed results here. A lot of puns, well, weren't puns. They were just jokes. I included some anyways, with an apology for the lack of pun.
-
There is one thing I didn't use any A.I. for: the ansi art that proliferates the python program. I made all of that by hand using a program called moebius
The future
I hope you like JellyML! Let me know if you have any suggestions
- mail me at: mike@jellyml.co
- or open an issue on GitHub: github.com/mmulet/jellyml
Secrets
I've hidden a few secrets in the website and in the program itself. I hope you can find them.
- There is a secret way to use the command line. There is a clue in each command's help message
- On the website, have you seen the tentacle!?
- There is a way to save the donut from the jelly tentacle.